Les minerais constituent un pilier essentiel de notre vie quotidienne, qu’ils se trouvent dans les voitures et les smartphones que nous utilisons, dans les infrastructures et l’architecture qui nous entourent, ou dans une multitude d’autres produits. Ils stimulent le développement économique de nombreux pays et pourraient devenir le moteur de celui de beaucoup d’autres. Néanmoins, souvent extraits et commercialisés dans des régions non sécurisées, frappées par la pauvreté et échappant à toute réglementation, ils peuvent aussi enrichir quelques poignées d’individus sans scrupules.
Avoir accès à des données fiables sur l’extraction et le commerce des minerais s’avère ardu. Cela peut être dû à des problèmes d’accès physique (par exemple au Myanmar ou en RDC), au fait que les entreprises et les gouvernements se montrent peu disposés à agir dans une plus grande transparence, ou à un manque de capacité technique des fournisseurs. En raison de ce déficit d’informations, il est d’autant plus difficile d’enquêter sur les pratiques des entreprises et d’exposer les actes répréhensibles.
L’importance de l’imagerie par satellite

Les forêts denses de l’est de la RDC et la couverture nuageuse tropicale pourraient avoir gêné la résolution des images satellites de Landsat. Image satellite voilée de Landsat 8 superposée sur une carte à haute résolution. Mine de Paradiso (site d’exploitation artisanale de l’or), province d’Ituri.
C’est là que les images satellites entrent en jeu. Les données générées par les satellites, et dans certains cas par les drones, pourraient fournir aux citoyens, aux chercheurs et aux journalistes un accès sans précédent aux marqueurs géographiques de l’activité minière. Ces données pourraient être utilisées pour vérifier les statistiques officielles et les divergences dans les signaux d’alerte relevés, ou en tant que variables de substitution lorsqu’il n’existe aucune statistique, devenant dès lors un outil important pour réclamer des comptes au secteur minier.
Si elles sont utilisées de façon responsable, les images satellites peuvent également être employées par les entreprises pour les aider à identifier les risques dans leurs chaînes d’approvisionnement (tels que des divergences entre la position géographique des mines et les statistiques d’exportations afin de déceler la contrebande transfrontalière) et par les gouvernements pour surveiller des régions pourtant difficilement accessibles.
Ici à Global Witness, nous avons passé manuellement en revue des images satellites à haute résolution pour obtenir l’éclairage nécessaire dans nos investigations, par exemple en observant l’extraction du talc par l’État islamique en Afghanistan et l’exploitation forestière en Papouasie Nouvelle Guinée. Mais cela requiert souvent une connaissance préalable de ce que l’on cherche, et, plus important peut-être, cela demande énormément de temps – c’est pratique lorsque la zone est petite, mais moins lorsqu’il s’agit d’une région plus étendue.
Le rôle de l’intelligence artificielle
Les évolutions dans l’intelligence artificielle et l’apprentissage automatique, aussi appelé apprentissage machine, peuvent apporter une solution aux défis posés par l’utilisation d’images satellites. Les algorithmes informatiques peuvent aujourd’hui être programmés pour rechercher dans des images des marqueurs spécifiques qui sont soit trop subtils pour être identifiés par un humain, soit prendraient trop de temps pour qu’un humain parvienne à les déceler.
Dans d’autres domaines, ces approches améliorent déjà notre vie. Des scientifiques ont élaboré des programmes qui sont meilleurs que les médecins pour détecter une maladie dans les scans rétiniens, et des images satellites accessibles au public sont déjà utilisées par les protecteurs de l’environnement pour détecter et estimer la diminution de la couverture forestière.
L’année dernière, Global Witness s’est associée à DataKind et NRGI pour explorer la faisabilité d’une utilisation d’images satellites et de l’intelligence artificielle pour déceler automatiquement certains types d’activité minière sur un large territoire. À notre connaissance, ce type de projet n’a jamais été réalisé avec succès auparavant.
Nous avons entrepris de mettre au point un programme informatique capable d’identifier automatiquement la position géographique de mines en utilisant l’imagerie par satellite. Dans le cadre de ce premier essai, nous nous sommes focalisés sur l’exploitation minière à petite échelle dans l’est de la République démocratique du Congo – pour deux raisons :
- Les petites mines
sont plus difficilement repérables que les mines industrielles plus grandes,
qui ont des marqueurs plus visibles et plus nombreux. Si nous y parvenions avec
les petites mines, nous savions que nous pourrions aussi aisément utiliser le
modèle/les données pour identifier les plus grandes.
- Nous avions des
« données d’apprentissage » facilement disponibles pour cette région
et ce type de mine.
L’apprentissage du modèle
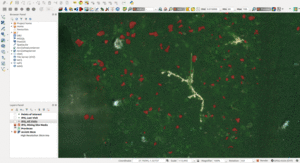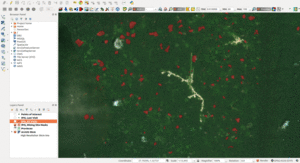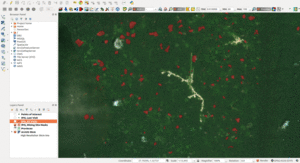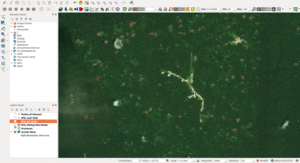
Pour mettre au point le modèle, nous avons utilisé une technique appelée l’apprentissage automatique ou apprentissage machine. L’apprentissage automatique est une branche de l’intelligence artificielle qui a une variété d’applications dans la vie quotidienne, de Google Translate au filtrage anti-spam. Statistiquement, nous avons cherché à prédire la position géographique de sites miniers. Cela consistait à attribuer une probabilité qu’un pixel déterminé d’un morceau d’image satellite représente en fait une partie de mine.
En premier lieu, nous avions besoin d’images satellites, et même de beaucoup d’images satellites. Il fallait qu’elles soient rapidement accessibles au logiciel que nous allions mettre au point et il fallait qu’elles soient gratuites. Étonnamment, un service appelé Google Earth Engine met aujourd’hui à disposition sur le cloud, précisément dans ce but, des données historiques du satellite Landsat. Landsat passe aux mêmes endroits sur terre tous les seize jours. Il s’agit d’un outil extraordinairement puissant qui vous permet d’analyser des changements dynamiques dans le paysage et l’environnement susceptibles d’indiquer la présence d’une activité minière.
En deuxième lieu, nous avions besoin d’un ensemble de données d’ « apprentissage » avec la position réelle de certaines mines artisanales connues. L’algorithme pouvait alors « apprendre » à quoi ressemble un pixel associé à une mine et prédire plus précisément où pourraient exister d’autres mines. Trouver un ensemble de données d’apprentissage de mines artisanales de l’est de la RDC aurait pu se révéler difficile, mais nous avons eu la chance d’avoir accès à des données collectées par l’International Peace Information Service (IPIS).
Notre équipe de volontaires experts en science des données a alors élaboré une application pour délimiter chacune des mines identifiées par IPIS, dessinant concrètement des formes dans des contours (voir image ci-dessous).
Ces formes – qui
représentaient des sites miniers connus – ont ensuite pu être introduites dans
notre algorithme d’apprentissage-machine pour l’apprentissage du modèle. Les
volontaires ont découvert que ce que l’on appelle les « forêts aléatoires » (rien à voir avec de vraies forêts !) étaient
les algorithmes les plus efficaces pour prédire l’existence de sites miniers.
L’efficacité du modèle a été évaluée en voyant combien de sites miniers connus (mais « non vus ») dans l’ensemble de données d’IPIS il était capable d’identifier précisément, alors que son apprentissage ne portait que sur une portion partielle des données. L’idée étant que plus il pourrait identifier ces sites miniers, plus il serait à même d’identifier des sites miniers totalement nouveaux ou non identifiés précédemment.
Les résultats se sont révélés prometteurs. Le meilleur modèle a pu identifier 79,7% des mines connues. L’inconvénient – et ce sur quoi il faudra travailler davantage – est que le modèle présentait un taux élevé de faux positifs. Cela signifie qu’il a souvent identifié des pixels associés à des mines à des endroits où aucune activité minière n’était présente. De tous les pixels qui ne représentaient pas des fragments de sites miniers connus, le modèle n’a pu identifier correctement que 48,4% d’entre eux.
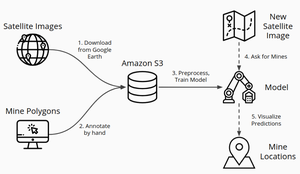
Diagramme du flux du traitement de données
Et maintenant ?
Bien que le modèle doive encore être considérablement peaufiné, il a clairement montré qu’il s’agissait d’une piste intéressante pour de futures recherches.
Comme avec toute technologie, il a ses limites et pourrait être détourné à des fins privées ou commerciales, ou il pourrait être utilisé à mauvais escient, contribuant alors à perpétuer certains modèles actuels de commerce irresponsable.
Afin d’atténuer ces risques, nous pensons que le développement open source – processus qui rend le code informatique et ses outputs librement disponibles pour tous – est un exercice crucial pour des organisations, telles que la nôtre, qui prônent l’obligation de rendre des comptes. Il crée des écosystèmes d’information qui servent l’intérêt du public et produisent des connaissances pouvant être utilisées par tout un chacun.
L’alternative est que l’innovation technologique ait lieu dans des écosystèmes propriétaires fermés ou « jardins clos ». Les systèmes propriétaires peuvent renforcer les asymétries d’information lorsque certains puissants acteurs – qu’il s’agisse de gouvernements, d’entreprises ou d’individus – suppriment des informations, qu’ils utilisent eux-mêmes à leur avantage.
Nous cherchons à travailler avec des technologues en RDC et ailleurs pour améliorer et explorer les applications des programmes que nous avons produits. Si vous vous sentez concerné, merci de prendre contact avec nous à cette adresse : [email protected].
DataKind a rendu open source tous les codes produits et nous espérons que cela pourra dynamiser l’innovation dans ce domaine au service du progrès social. Pour les développeurs, les pirates informatiques citoyens et les universitaires intéressés dans l’élaboration du modèle que nous avons créé, le code source est disponible ici sur Github.
Remerciements
Un merci tout particulier à DataKind et aux volontaires qui ont travaillé sur ce projet :
- Krishna Bhogaonker, Université de Californie, Los Angeles
- Daniel Duckworth, Google Brain
- Junchuan Fan, Université de Maryland, College Park
- Sina Kashuk, DataKind
- Ryan Vilim, Sidewalk Labs
- Katie Yoshida, Foursquare


